(This blog post was originally published at Thumbtack Engineering.)
Thumbtack helps customers tackle their to-do list by connecting local professionals with the right customers all across the nation. Our teams are focused on building out this two-sided marketplace and creating the tools to enable pros to manage and scale their business.
When it comes to building products, Thumbtack takes a data-driven approach that relies heavily on experimentation and iteration. At any given point in time, we’re running dozens of A/B tests that touch multiple features and product flows.
However designing A/B tests correctly is not always simple, given the marketplace nature of our platform and the breadth of categories we support. In this blog post, we’ll discuss some of the challenges in setting up A/B tests and explore the evolution of Seedfinder, the infrastructure we built to allow our data scientists to sleep more soundly.
The Challenges
Pre Experiment Imbalance
One major challenge in designing an A/B test is accounting for inherent imbalances between test buckets. In one instance, we performed an A/A test comparing the same version of landing pages in different markets and saw a 5% lift in metrics for the treatment vs. baseline bucket. Pre-experiment imbalance affects our ability to draw reliable conclusions from experiment results.
This issue can be mitigated through repeated randomization of A/A tests to find a seed that balances metrics adequately across experiment buckets. More info can be found in this blog post, including all the statistics behind this approach.
Limited Data Scientist Resources
Initially, our data scientists manually ran R/Python scripts to account for pre-experiment imbalance. These scripts required a lot of attention and took several hours to run. While this ad hoc approach allowed us to run certain experiments, this process clearly would not scale as the number of experiments increased.
Custom Experiment Population
As Thumbtack continues to grow, so does the complexity of experiments. There is an increasing number of experiments that target a specific subset of users. Instead of placing an additional burden on data scientists, we want to enable developers to easily describe the population to experiment on.
The Infrastructure
In order to keep up with the increasing demand for experiments, we built a self-serve automated system for setting up experiments. Here’s how our infrastructure evolved over time.
As part of the service-oriented architecture migration efforts, experiment assignment logic was broken out to its own service.
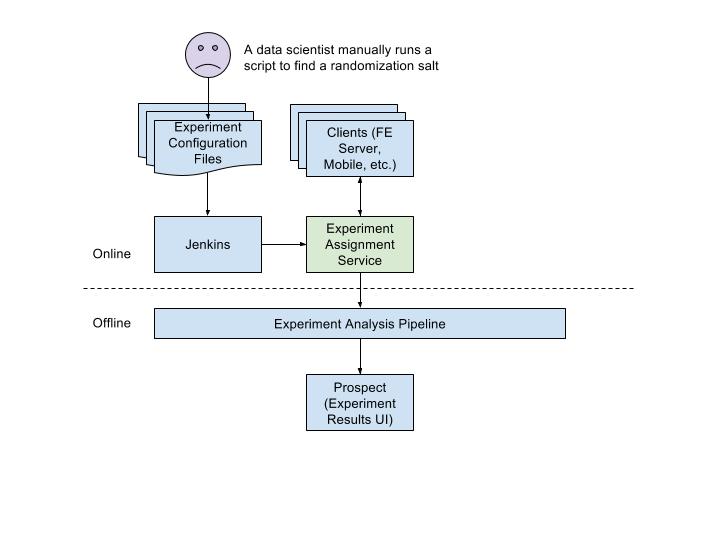
To start a new experiment, developers can commit a configuration file to a git repo which automatically syncs the experiment definition to the Experiment Assignment Service (EAS). Clients can then reference this experiment in code (website, mobile, or other services).
In order to move from a manual process using R/Python scripts to a fully automated system, we first needed to improve the performance of the existing process.
Rewrite using Scala/Spark
The biggest pain point of our previous setup was the time it took for the R/Python scripts to run. These scripts often took hours on a laptop because 1) the scale of our data and 2) the thousands of iterations of repeated A/A tests. However, the nature of this computation lends itself to parallelization. We leveraged our existing data infrastructure and rewrote the scripts using the distributed computing framework, Spark.
Our current data infrastructure is built on top of Google Cloud Platform. We use a combination of Google Cloud Storage, Google Cloud Dataproc (Spark) and Google BigQuery (SQL) to power our offline jobs. For more details, check out this blog post on our journey moving to GCP.
The Seedfinder Spark job is triggered when a new seedfinder experiment is synced with EAS. This new experiment will be in a “pending” state until the Seedfinder Spark job successfully finds a randomization salt and updates EAS.
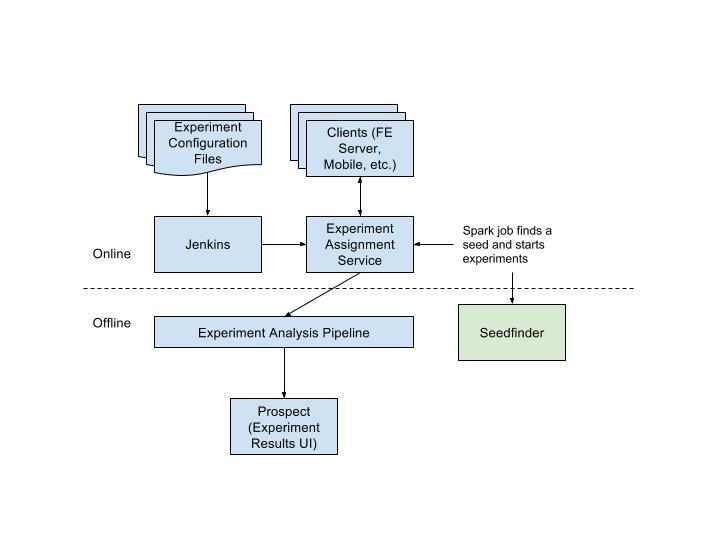
The Seedfinder job now takes only minutes — a 10X improvement in runtime and saves the operational overhead for our data scientists by automating the end to end process.
Customization
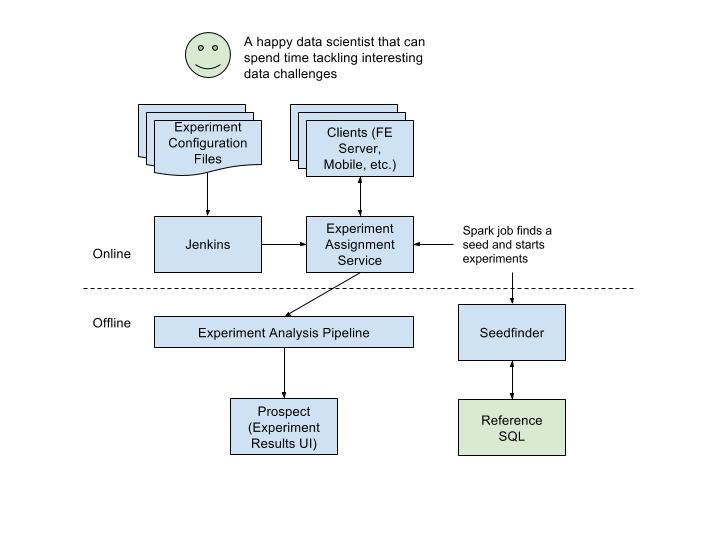
As Thumbtack continues to grow, so does our need to experiment on a specific subset of our users. To address this need, we added a feature that lets developers specify the subset of users for an experiment via a reference table.
A reference table contains the set of users who should participate in the experiment. This table is automatically exposed as a BigQuery table when developers commit SQL logic to a git repo. Developers can configure their experiments to use reference tables in experiment configuration, and the Seedfinder Spark job reads data from reference tables as necessary.
Putting it all together
Here’s how the Seedfinder architecture looks like today:
Takeaways
There are a couple of things we learned along the way:
- Prioritizing projects at the “right” time. We always knew the manual process to find a seed was not sustainable. However, at the time, there were more pressing projects to tackle, given the low volume of experiments that needed Seedfinder and our limited engineering resources (we are actively #hiring). We chose to solve this problem when the demand for seedfinder experiments kept rising.
- Running online A/B experiments is tricky. This blog post only touches the tip of the iceberg when it comes to the challenges we encounter running experiments in an online marketplace. The interactions between customers and professionals in a two-sided marketplace experiment makes inference using classic techniques challenging. If you are a seasoned data scientist, we have interesting data problems to solve here at Thumbtack!