Predictive models, a.k.a. machine learning models (if you prefer the buzzword), play huge parts in today’s technology companies. They are used to uncover valuable patterns from mass datasets that are just too complicated for humans to consume directly. Spark is a large-scale data processing engine that handles large datasets efficiently in a distributed way. Given Spark’s already high adoption as the data process engine and its rapid development in machine learning modeling, it is natural for many companies to build its machine learning eco-system around Spark.
The Spark MLlib library provides an easy-to-use model train/test process that is familiar to data scientists to play around and fine tune predictive models. A pretty standard offline model training process often involves these following steps, which are wrapped into a pipelining type of operations in Spark MLlib (see examples).
- Load historical data
- Feature extraction/engineering
- Model training
- Model evaluation
However, deploying predictive model to a production environment, or serving the model in production, is a bit more complicated. Its architecture largely depends on how the model will be used. At very high level, predictive models often are used to score some instances, e.g. the risk score of fraud transaction or the likelihood of clicking on ads. This scoring operation can be offline or online, depending on its application. Offline scoring means the model doesn’t needs to score an instance in real-time and online scoring means the model is required to score with real-time input and low-latency. In this post, I am going to touch on a few common architectures and their use cases.
Batch prediction
For models used for offline scoring, we can used the batch prediction architecture. That is, we don’t really serve the model online; instead, the actual scoring happens in batches offline and we just need to serve the scores produced by the model online. This architecture can be combined with the offline model training setup because both are in an offline environment. We can directly use Spark MLlib’s model training pipeline to fit a model and then store the predicted scores into a database and let our online service talks to that database to serve the scores.
This architecture can be summarized as
Hard-coded model
For online scoring, we do need to serve the model itself online to respond to incoming signals in real-time. A simply, but effective architecture is to hard code the actual model into your online serving service. This is straightforward for regression based models, such as linear regression and logistic regression. Since the scoring logic of these models can be explicitly coded up easily. At the end of the day, scores from regression based models are just a multiplication of features with its fitted coefficients. Note that the feature generation logic should be the same between offline model training and online scoring. In this case, we just need to store coefficients from offline training into a database so that the online serving service has access to it in order to implement the scoring logic.
This architecture can be summarized as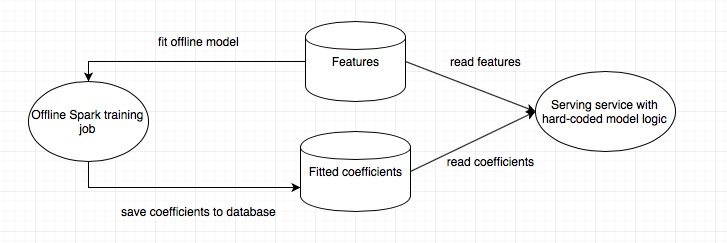
Model persistence
For more sophisticated model, the hard-coded model logic can get very complicated and error-prone. It is preferred to serve the offline trained model directly to production. Luckily, with latest Spark, we can persistent the trained model/pipeline into a physical storage and then load it back for scoring. This can be easily achieved via the following command.1
2
3
4
5
6// suppose we have a trained RandomForestClassificationModel model
trainedModel.save("s3n://.../trainedModel")
// load the same model back
val sameTrainedModel =
RandomForestClassificationModel.load("s3n://.../trainedModel")
Internally, the model metadata and parameters are saved as JSON and the data as Parquet. One thing to call out here, in order for this to work, the online service needs to run Spark in local mode; otherwise, it can get a little tricky to load the model back.
Compared to the architecture of hard-coded model, we directly save the model to storage and load it for scoring. The logic is pretty straightforward and can support more models, although it is not as light-weighted as the previous approach, due to extra requirements on the serving service.
This architecture is similar to the hard-coded model, but store the trained model directly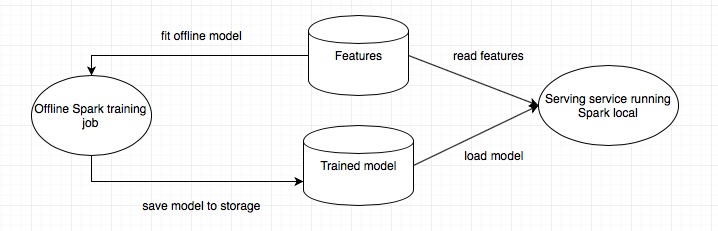
Predictive Model Markup Language (PMML)
More generally, we can use the Predictive Model Markup Language (PMML) to represent predictive models and communicate it to other language/framework. The idea is similar to how web services talk to each other via a standard protocol such as JSON or Thrift. PMML is the de facto standard language used to represent predictive analytic models. It is based on XML and allows for predictive solutions to be easily shared between PMML compliant applications. Spark supports model export to PMML for a list of models, such as LinearRegressionModel, RidgeRegressionModel and LassoModel (see full list). Interestingly though, Spark doesn’t support load model from PMML directly. But the one-way conversion is very easy using the following syntax.1
2// suppose we have a trained model
trainedModel.toPMML("/tmp/trainedModel.xml")
Again, the architecture is very similar to model persistence, since we just use another format to represent the model in storage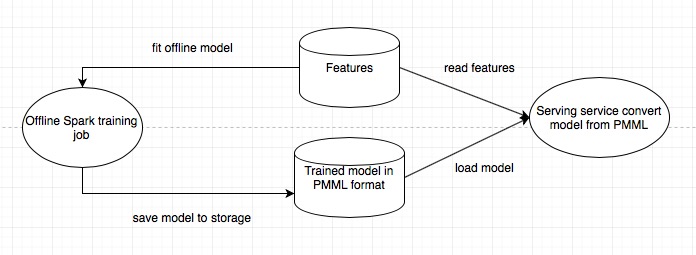
Summary
From prototype to production often involves a whole set of different considerations and trade-offs. Some extra implementation work must be done to make a balance between a fast iterating offline training pipeline and a robust online model serving service. It is great that Spark provides us with different options so that we can leverage them based on our specific use cases.
Of course, there are other interesting topics around deploying predictive model to production that I am very interested in and will write about later. For example, how do we think about regular model update/re-train and how to leverage our A/B testing framework to automate this process? If you are interested as well, stay tuned (updated: Predictive Model System - Some Missing Components)!